前言
在深度学习任务管理中,了解服务器的资源使用情况至关重要。基于服务器的资源的使用情况,能够有效分析程序是CPU使用密集还是GPU使用密集,优化程序运行性能。本文将介绍如何使用top和gpustat命令来监控和分析服务器的CPU和GPU负载情况。
CPU负载分析:使用top命令
基本使用
1 | top |
top界面解析
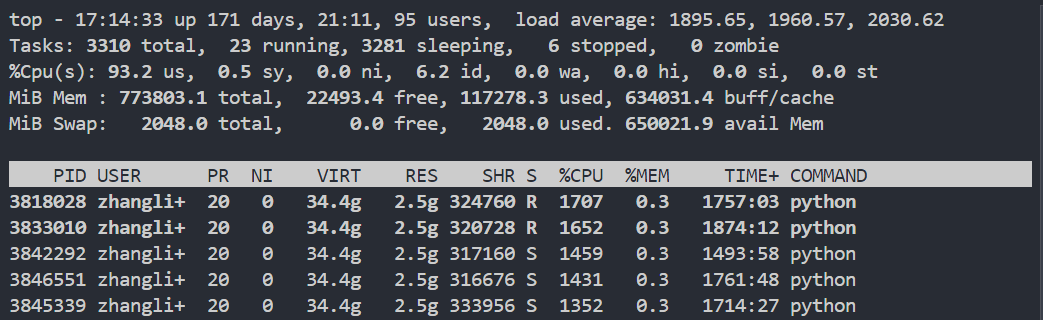
- 系统信息概览(第1-5行):
第1行:系统运行时间、用户数、负载均衡
- load average后的三个数字分别表示1分钟、5分钟、15分钟的平均负载
- 数值不应超过CPU核心数,否则表示系统超负荷
第2行:任务信息
- total:进程总数
- running:正在运行的进程数
- sleeping:睡眠的进程数
- stopped:停止的进程数
- zombie:僵尸进程数
第3行:CPU使用率
- us:用户空间占用CPU百分比
- sy:内核空间占用CPU百分比
- ni:用户进程空间内改变过优先级的进程占用CPU百分比
- id:空闲CPU百分比
- wa:等待输入输出的CPU时间百分比
第4-5行:内存使用情况
- Mem:物理内存
- Swap:交换空间
- 进程信息(第7行开始):
- PID:进程ID
- USER:进程所有者
- PR:进程优先级
- NI:nice值(负值表示高优先级,正值表示低优先级)
- VIRT:虚拟内存使用量
- RES:实际物理内存使用量
- SHR:共享内存大小
- S:进程状态
- %CPU:CPU使用率
- %MEM:内存使用率
- TIME+:进程使用的CPU时间总计
- COMMAND:进程名称
常用交互命令
- P:按CPU使用率排序
- M:按内存使用率排序
- T:按运行时间排序
- k:终止进程(需要输入PID)
- r:重新设置进程优先级
- q:退出top
GPU负载分析:使用gpustat

安装gpustat
1 | pip install gpustat |
基本使用
1 | gpustat |
输出解析
每个GPU的信息包含:
- GPU ID:显卡编号
- 显卡型号
- 温度信息
- GPU利用率
- 显存使用情况:已用/总量
- 运行在该GPU上的进程信息
高级用法
实时监控(每秒更新):
1
gpustat -i 1 # -i 默认1秒更新
显示详细进程信息:
1
gpustat -cp
显示功率使用情况:
1
gpustat --show-power
分析要点
CPU负载分析
- 系统负载
- 负载值/CPU核心数 < 0.7:系统很闲
- 0.7 - 1.0:系统正常
1.0:系统繁忙
ℹ️ 提示:CPU核心数 可以使用
lscpu或nproc查看
- CPU使用率
- 高us:用户进程消耗CPU
- 高sy:内核消耗CPU,可能有系统调用过多
- 高wa:IO瓶颈
- 高id:CPU较空闲
GPU负载分析
- 显存使用
- 查看是否有显存泄漏
- 进程结束但显存仍被占用
- 程序长时间运行,显存只增不减
- 评估任务是否合理分配显存
- GPU使用率
- 低使用率可能表示数据加载成为瓶颈
- 持续100%表示计算密集型任务正常运行
- 温度监控
- 通常应保持在85℃以下
- 持续高温需要检查散热情况

